I’m unable to load the app (“web page not available”) on Android, and the beestat.io site isn’t loading, either.
Is there some maintenance happening at the moment?
I’m unable to load the app (“web page not available”) on Android, and the beestat.io site isn’t loading, either.
Is there some maintenance happening at the moment?
Back up! Sorry not sure what caused the outage - something crashed the app server again. Investigating.
No worries, thanks Jon!
If you ever have need of a Staff SRE to help investigate stability issues, let me know. It would be fun to see if I can contribute to your project in any way.
Down for me as well.
Got my streams crossed a bit here. There have been two separate issues:
The web server crashed (third time in a week). I haven’t identified the exact cause of this issue except for a short load spike and then a crash. I did (hopefully) add an auto-restart to the server so a crash should recover quickly and not cause an outage for the entire evening. This would cause beestat to just not load or get a “page cannot be displayed” etc.
An unrelated change to add the quick thermostat switcher introduced a bug that could cause beestat to not load for devices with too small of a pixel width. I have now resolved this. This would cause beestat to get stuck on the loading screen.
Apologies for the issues!
Forgot to reply to you. If you’re ever interested, here’s more about beestat’s infrastructure. The stack is very simple and has been insanely reliable.
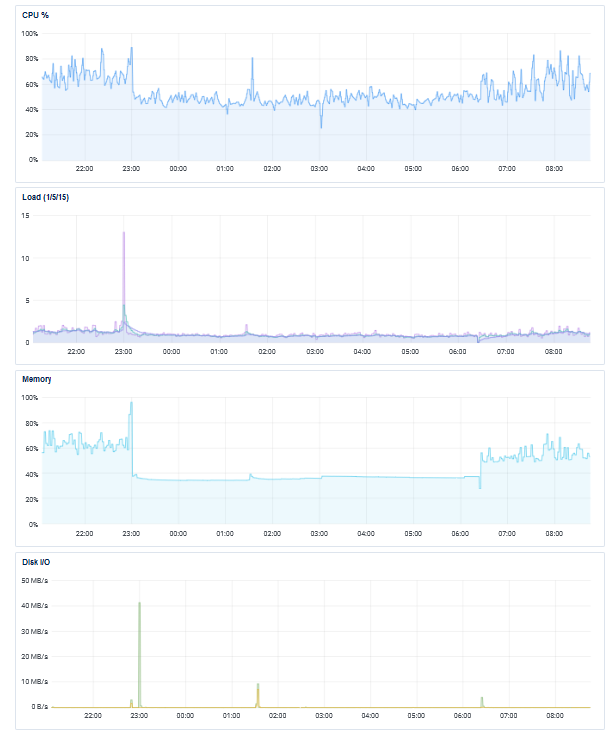
I still need to look at the logs in more detail, but here’s what the most recent crash looks like on the app server. Big IO/load spike then Apache says goodnight.
Ooooh, thanks for the link to the infrastructure page! No kidding about simple, that’s great. And I’m glad to see Sentry has been meeting your needs!
That timing on the I/O spike strikes me as suspicious; anything happening right at the top of the hour like that feels immediately like a cron job running somewhere; given the huge spike in load, I’m curious if there’s a particularly IO-heavy transaction or method that was kicked off at that time from an automated source. Does Sentry give you any ideas on how distributed that load was?
Very much appreciate your transparency on this - getting to see the ins and outs of all of it is a cool opportunity.
As far as the Apache server goes, it’s doing a near-constant background sync of thermostat data. If one of those ran into an issue, usually it would just throw an exception or cause that process to run out of memory and be killed. There aren’t any other cron jobs specifically related to the app server.
Apache was killed by “oom-kill” when the server memory usage went from 60% memory usage → 100% memory usage. With only 1GB of memory, that’s not all that much. Every now and then I have an Apache process that uses more than the memory limit. Just two of these happening at the same time would have used the remaining memory and started causing the disk to swap and then Apache itself just getting killed.
Easy solution: Add more memory. At some point I should also investigate those processes that are running out of memory and address that.
Edit: Sentry doesn’t capture any of this. I only use Sentry for application logs, not server logs.
Would a simple solution be restart the process nightly… .Say sometime in the middle of the night?
Not exactly. The issue is not that there is an ever-increasing number of requests which eventually causes memory to run out.
The issue is that, sometimes, a bunch of requests come in all at once. There is an upper limit on number of simultaneous requests, and an upper limit on the amount of memory a single request can use. Those are great…but sometimes we are under both of those limits and the server still just doesn’t have enough memory to handle them. As long as the server load is still low, then the server memory is the bottleneck and should be increased.
Tell me about it! I also have a tiny AWS instance w/ 0.5GB of ram, & a 1.0GB swap file. I’ve had hackers try to crash it. I swap like crazy, but I don’t crash. It only gets slow when users pound on the keyboard because the response is not quick enough for their “needs”. I run Apache & a PostgreSQL (v13) 32GB DB.
I know it’s a bit of work, but can you cache the user data on the client (user) side on the initial request? And then do just incremental data uploads on successive requests. Of course, the data would go away on the client side when the web page is exited.
I actually do cache API responses on the client. When the server responds, it sends some headers telling the client how long to cache the response for. This helps a good deal and is likely one of the reasons I’ve made it this long with so little memory. Caching helps mitigate those bigger requests.